
Introduction
In modern serverless or event-driven architectures, data changes should not exist in isolation. Typically, these changes need to trigger reactions such as updates, data synchronization or notifications.
DynamoDB Streams captures every change that happens to items in any DynamoDB table and makes that data available almost instantly. We can process these changes using Lambda functions, Kinesis, or even build our own custom consumers with Node.js.
DynamoDB Streams Explained
DynamoDB Streams is a time-ordered sequence of item-level changes (insert, update, remove) in a table.
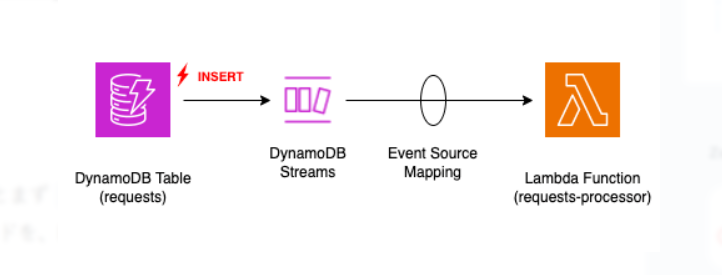
DynamoDB Streams
Each stream record represents a modification event and contains:
- The type of operation (INSERT, MODIFY, REMOVE)
- The keys of the modified item
- The old and/or new image of the item (depending on stream view type)
- Metadata like sequence number and event time
We can configure a stream to capture:
| Stream View Type | Description |
|---|---|
| KEYS_ONLY | Only primary key attributes |
| NEW_IMAGE | Entire item after modification |
| OLD_IMAGE | Entire item before modification |
| NEW_AND_OLD_IMAGES | Both old and new versions |
Configure and enable streams
To use DynamoDB Streams, we first need to enable streams on our table.
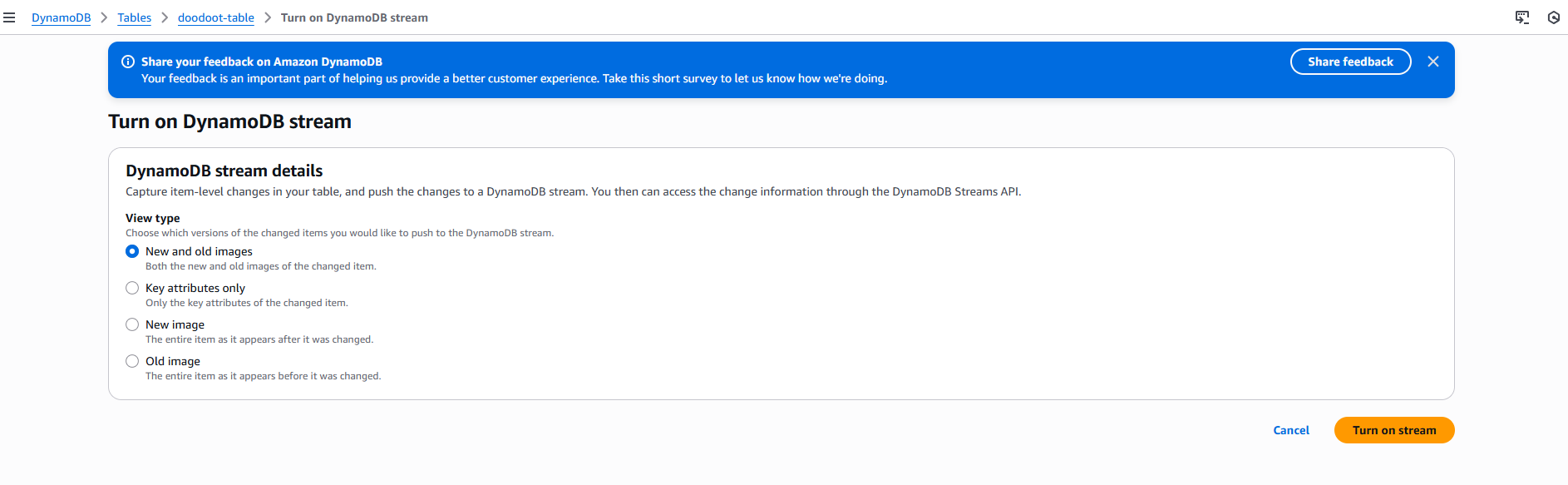
Enable streams from the console
To enable streams, go to the DynamoDB console and select your table. Navigate to the Exports and streams tab, then click Enable under DynamoDB stream details. Choose your preferred stream view type (KEYS_ONLY, NEW_IMAGE, OLD_IMAGE, or NEW_AND_OLD_IMAGES) and click Enable stream to confirm. Alternatively, you can use the AWS CLI with the update-table command and the --stream-specification parameter to enable streams programmatically.

Stream enabled for doodoot-table
To actually use DynamoDB Streams with Lambda, Kinesis or manual NodeJS Consumer, we need to set up some configuration. Here's what each integration requires:
Connecting to Lambda
We need to create an event source mapping that links our DynamoDB Stream to our Lambda function. Our Lambda function also needs IAM permissions to read from the stream—things like dynamodb:GetRecords, dynamodb:GetShardIterator, and dynamodb:DescribeStream. We can also configure settings like batch size, starting position, and how to handle errors.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams"
],
"Resource": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/stream/*"
}
]
}Connecting to Kinesis Data Streams
For Kinesis, we'll enable Kinesis Data Streams for DynamoDB, which is actually a separate feature from DynamoDB Streams. We configure the Kinesis stream as a destination, and we'll need IAM permissions that allow DynamoDB to write to our Kinesis stream.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:PutRecord",
"kinesis:PutRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws:kinesis:REGION:ACCOUNT_ID:stream/STREAM_NAME"
}
]
}Building a Custom Consumer
If we're building our own consumer with Node.js, we'll need the AWS SDK installed. Our application needs IAM credentials with the right permissions to read from DynamoDB Streams, and we'll manually poll the stream using SDK methods.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeStream",
"dynamodb:ListStreams"
],
"Resource": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/stream/*"
}
]
}All these integrations require some setup mainly around permissions and connecting the services together.
Architectural Patterns
DynamoDB Streams enables several powerful architectural patterns that help us build scalable and event-driven applications. Here are some common patterns we can implement:
Event-Driven Architecture
We can use DynamoDB Streams to trigger Lambda functions automatically whenever data changes in our table. This allows us to build reactive systems where different parts of our application respond to data changes without tight coupling.
Data Replication
Streams make it easy to replicate data across different tables, regions, or even different databases. We can capture changes in one table and automatically propagate them to another location, ensuring data consistency across our infrastructure.
Real-Time Analytics
By connecting DynamoDB Streams to Kinesis Data Streams, we can send change data to analytics pipelines for real-time processing. This is useful for generating dashboards, tracking metrics, or detecting patterns as data changes.
Audit Logging
We can capture every change made to our DynamoDB table and write it to a logging system or an S3 bucket. This creates a complete audit trail of all modifications, which is essential for compliance and debugging.
Cache Invalidation
When data in DynamoDB changes, we can use Streams to automatically invalidate or update caches (like ElastiCache or CloudFront). This ensures our cached data stays in sync with the source of truth.
Aggregation and Materialized Views
We can use Streams to maintain aggregated data or materialized views in separate tables. For example, when individual sales records are added, we can automatically update summary tables with totals and statistics.
Cross-Service Communication
Streams act as a bridge between DynamoDB and other AWS services. We can trigger Step Functions workflows, send notifications via SNS, or invoke other microservices based on database changes.
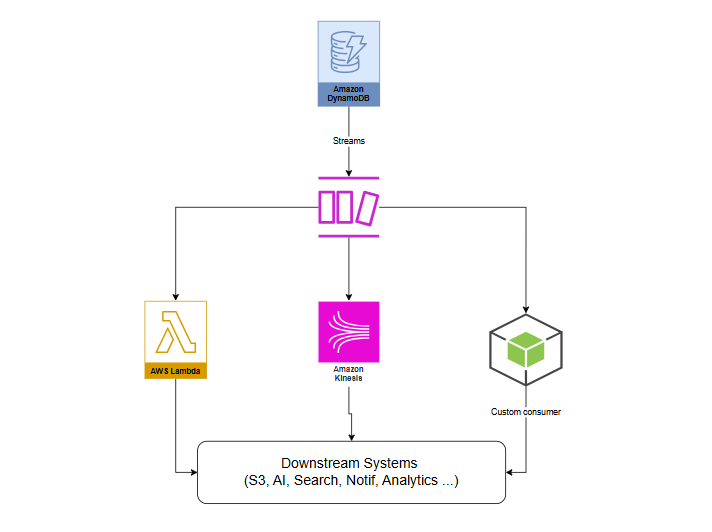
Architecture Overview
Connecting to Lambda function
To connect DynamoDB Streams with Lambda, we first need to make sure streams are enabled on our DynamoDB table with the appropriate stream view type. Once that's configured, we can set up the Lambda trigger:
- Go to the AWS Lambda console and either create a new function or select an existing one.
- Navigate to the Configuration tab and click on Triggers.
- Select Add trigger and choose DynamoDB as the trigger source.
- Select your table from the dropdown menu.
- Configure the batch size (how many records Lambda processes at once) and starting position (LATEST for new changes or TRIM_HORIZON for existing records).
- Optionally, set up error handling options like retry attempts and failure destinations.
- Save the trigger, and Lambda will automatically start polling your DynamoDB Stream and invoking your function whenever new records are available.
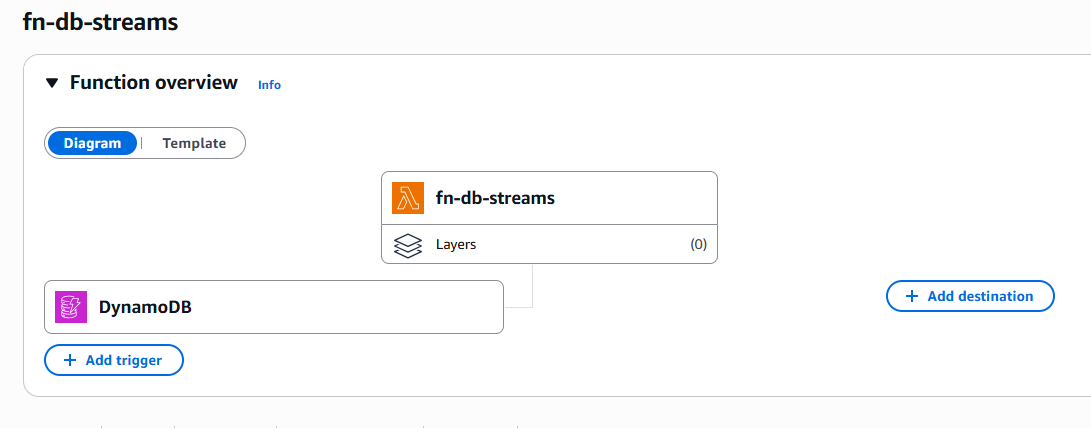
Added Lambda as a trigger
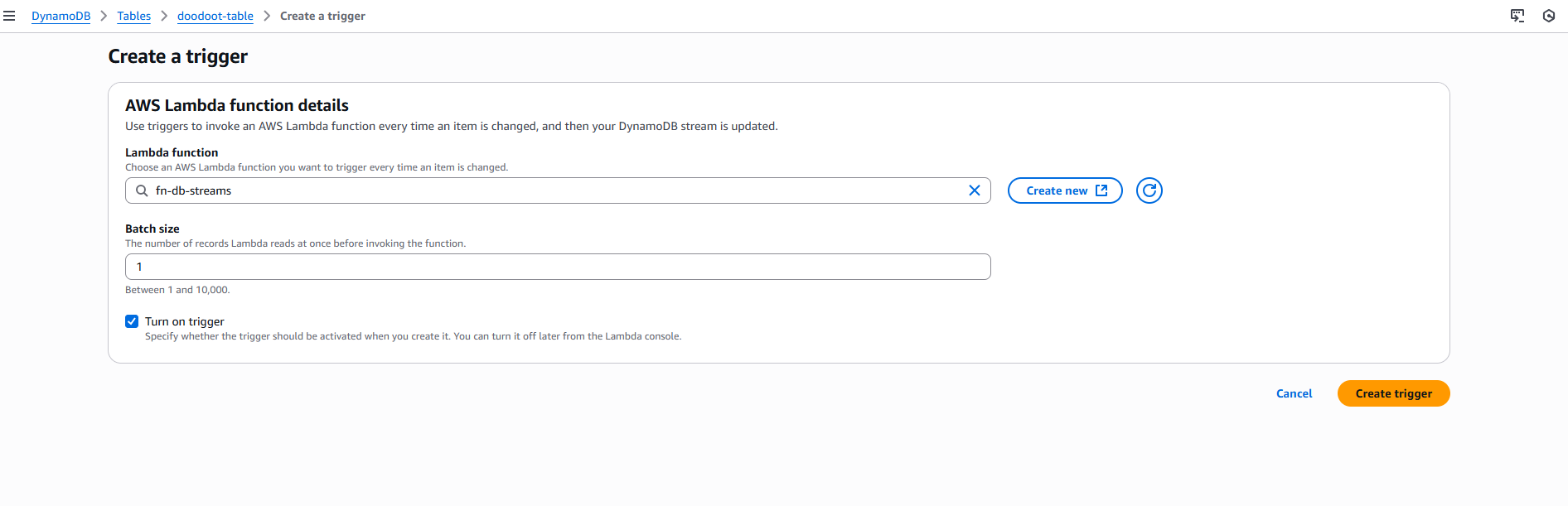
Creating the trigger
To handle the records coming from the stream, we can use the following code to iterate through each record and perform actions like forwarding them to downstream services such as S3, SNS, or SQS.
export const handler = async (event) => {
for (const record of event.Records) {
console.log('Event:', record.eventName);
console.log('Keys:', record.dynamodb.Keys);
}
};The stream can also be used to automatically replicate data to another DynamoDB table in a different region. Whenever an item is inserted, updated, or deleted in the source table, our consumer captures that change and writes it to the destination table, creating a cross-region backup or multi-region setup.
if (record.eventName === 'MODIFY') {
await replicaClient.putItem({
TableName: 'doodootiReplica',
Item: record.dynamodb.NewImage,
});
}Connecting to Kinesis Data Streams
DynamoDB can directly replicate stream data to Kinesis Data Streams using the Kinesis Data Streams for DynamoDB feature. This integration allows us to fan out stream records to multiple consumers and leverage Kinesis's advanced stream processing capabilities.
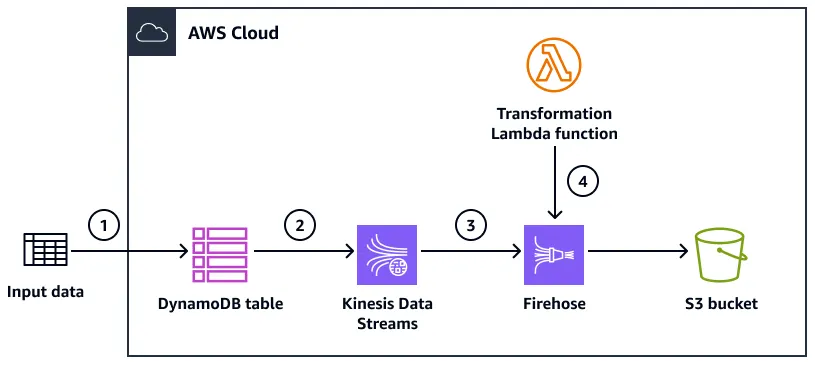
Example workflow for delivering records from DynamoDB to Amazon S3
Steps to Enable Kinesis Integration
- First, create a Kinesis Data Stream in the same region as your DynamoDB table if you don't have one already.
- Go to the DynamoDB console and select your table.
- Navigate to the Exports and streams tab.
- Scroll down to the Kinesis data stream details section.
- Click Enable Kinesis streaming destination.
- Select your Kinesis stream from the dropdown or enter its ARN.
- Click Enable to start streaming.
Once enabled, DynamoDB will automatically replicate all item-level changes to the Kinesis stream. From there, we can process the data using Kinesis Data Analytics, Kinesis Data Firehose for delivery to S3 or Redshift, or multiple Lambda consumers for parallel processing.
Building a Custom Consumer
Now let's see how to build a custom consumer in Node.js using the AWS SDK.
Why build a custom consumer? Sometimes we need more control over how we process stream records, or we want to integrate with systems that don't have native AWS support. Building our own consumer gives us that flexibility.
Let's see how this works in practice.
import { DynamoDBClient, UpdateTableCommand } from '@aws-sdk/client-dynamodb';
import { DescribeTableCommand } from '@aws-sdk/client-dynamodb';
import {
DynamoDBStreamsClient,
DescribeStreamCommand,
GetShardIteratorCommand,
GetRecordsCommand,
} from '@aws-sdk/client-dynamodb-streams';
const client = new DynamoDBClient({ region: 'eu-central-1' });
const streamsClient = new DynamoDBStreamsClient({ region: 'eu-central-1' });Sets up the AWS SDK clients needed to work with DynamoDB and DynamoDB Streams. We import the necessary commands for enabling streams, describing tables, and reading stream records. Then we create two clients: one for DynamoDB operations and another for DynamoDB Streams operations, both configured for the eu-central-1 region.
async function consumeStream(streamArn) {
console.log('Starting stream consumer...');
const { StreamDescription } = await streamsClient.send(
new DescribeStreamCommand({ StreamArn: streamArn })
);
console.log(`Found ${StreamDescription?.Shards?.length || 0} shard(s)`);
for (const shard of StreamDescription?.Shards ?? []) {
const shardId = shard.ShardId;
console.log(`\nProcessing shard: ${shardId}`);
const { ShardIterator } = await streamsClient.send(
new GetShardIteratorCommand({
StreamArn: streamArn,
ShardId: shardId,
ShardIteratorType: 'TRIM_HORIZON',
})
);
let iterator = ShardIterator;
while (iterator) {
console.log('Polling for records...');
const { Records, NextShardIterator } = await streamsClient.send(
new GetRecordsCommand({ ShardIterator: iterator })
);
console.log(`Found ${Records?.length || 0} record(s)`);
for (const record of Records ?? []) {
handleRecord(record);
}
iterator = NextShardIterator;
await new Promise((r) => setTimeout(r, 2000));
}
}
console.log('Stream consumer finished');
}Reads from the DynamoDB Stream by looping through all shards and processing records from the oldest available ( TRIM_HORIZON). It continuously polls for new records every 2 seconds, processes each one through handleRecord, and keeps listening for changes to the table.
function handleRecord(record) {
console.log('Handle the record...');
}Defines the handleRecord function where we implement our custom logic to process each stream record. In this example, it simply logs a message, but in a real application, this is where we'd put any business logic we need for updating a cache, sending notifications, transforming data, or triggering other workflows.
async function main() {
const { Table } = await client.send(
new DescribeTableCommand({ TableName: 'doodoot-table' })
);
console.log('Stream ARN:', Table?.LatestStreamArn);
consumeStream(Table?.LatestStreamArn);
}
main();The main function brings everything together. It retrieves the table information to get the Stream ARN, logs it to the console, and then starts the consumer by calling consumeStream with that ARN. This kicks off the entire stream processing workflow.
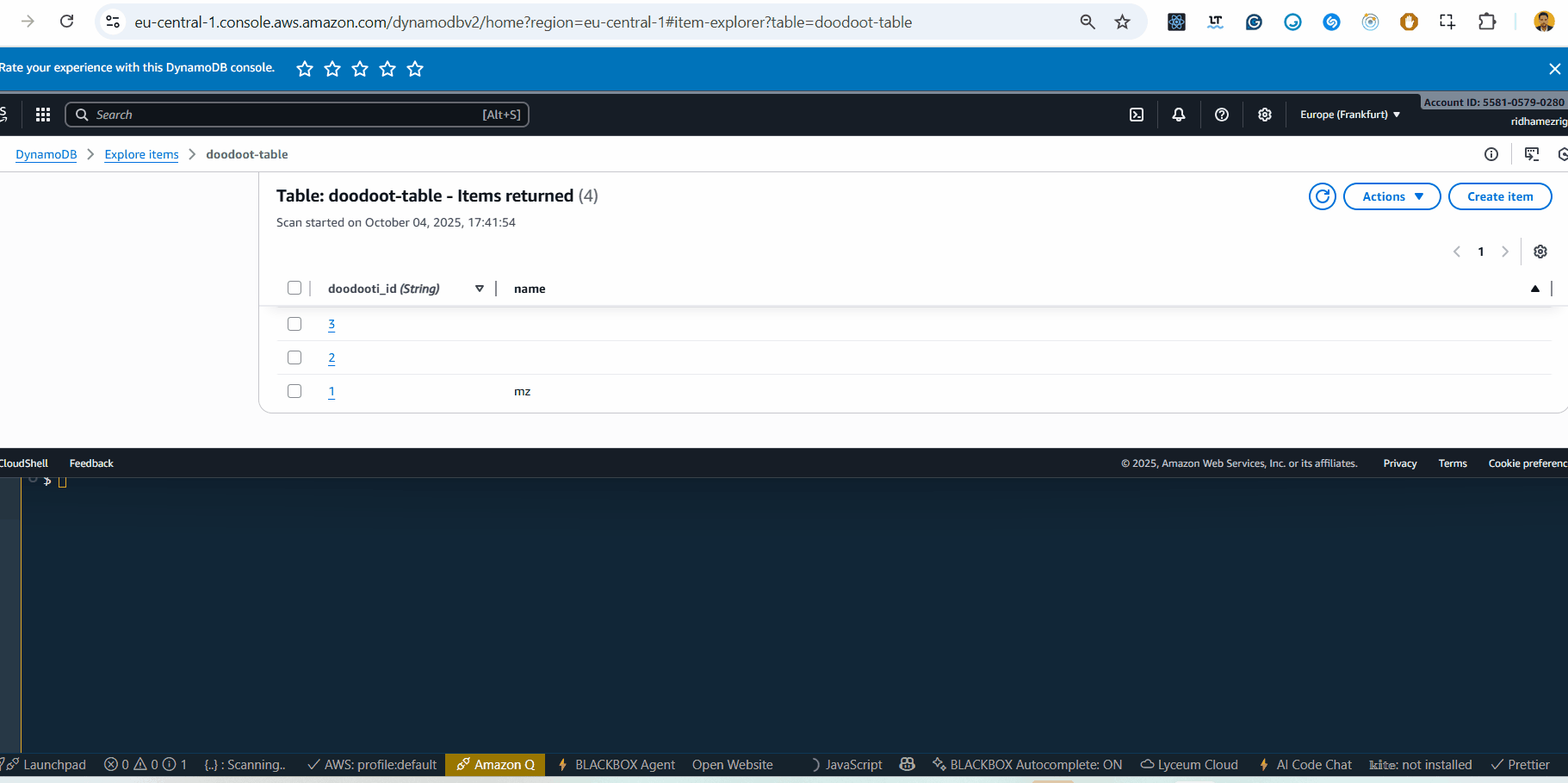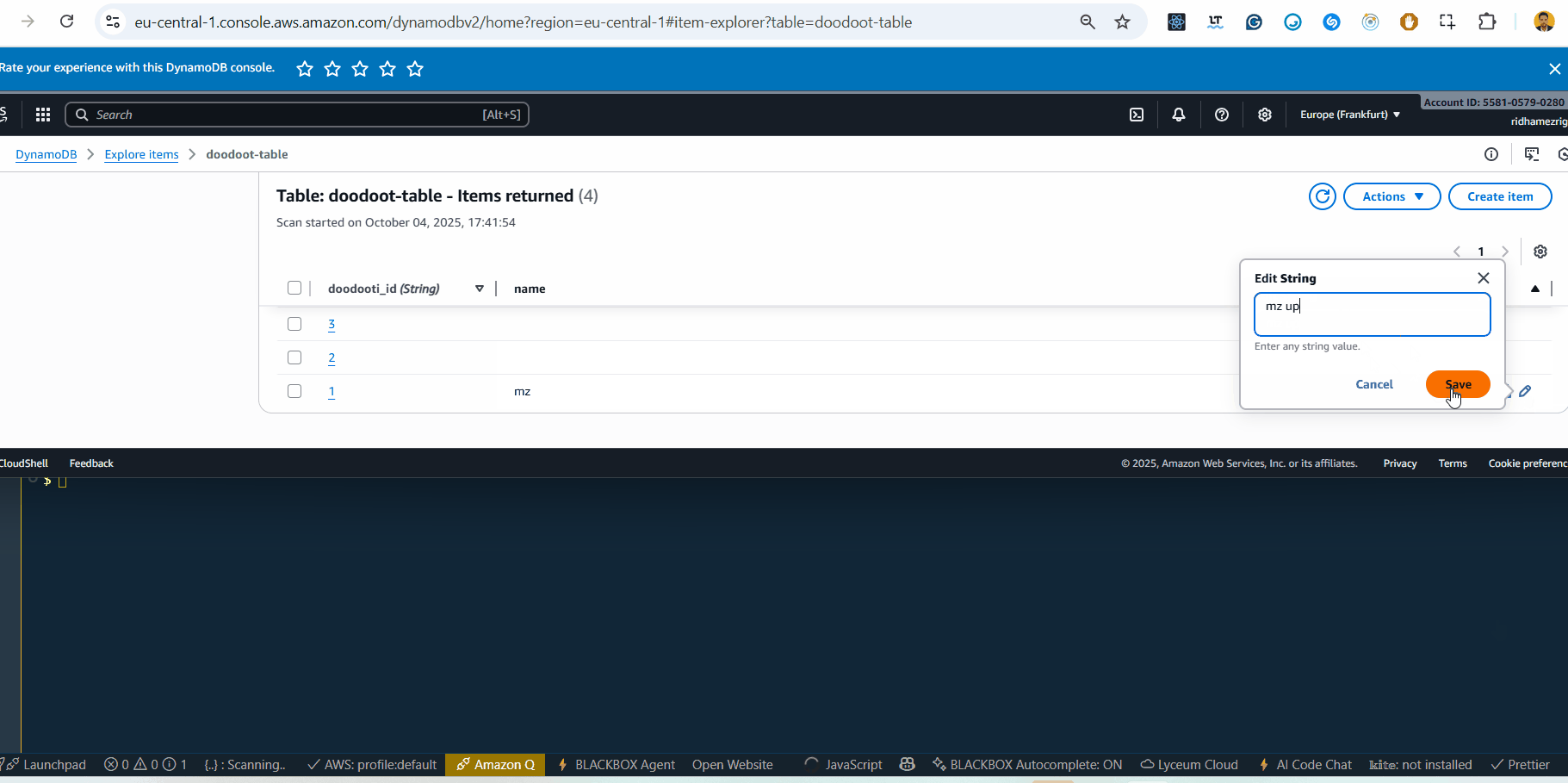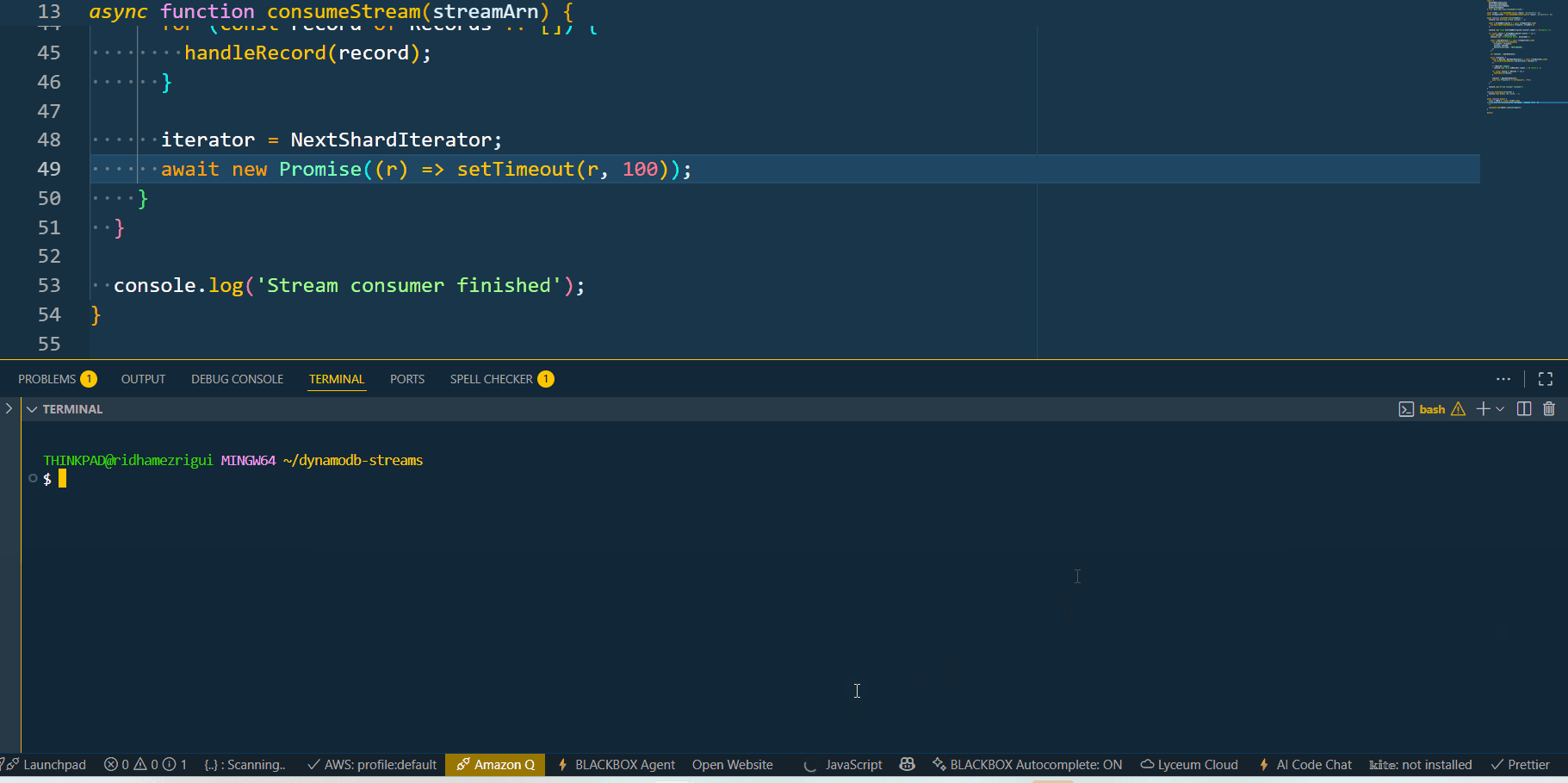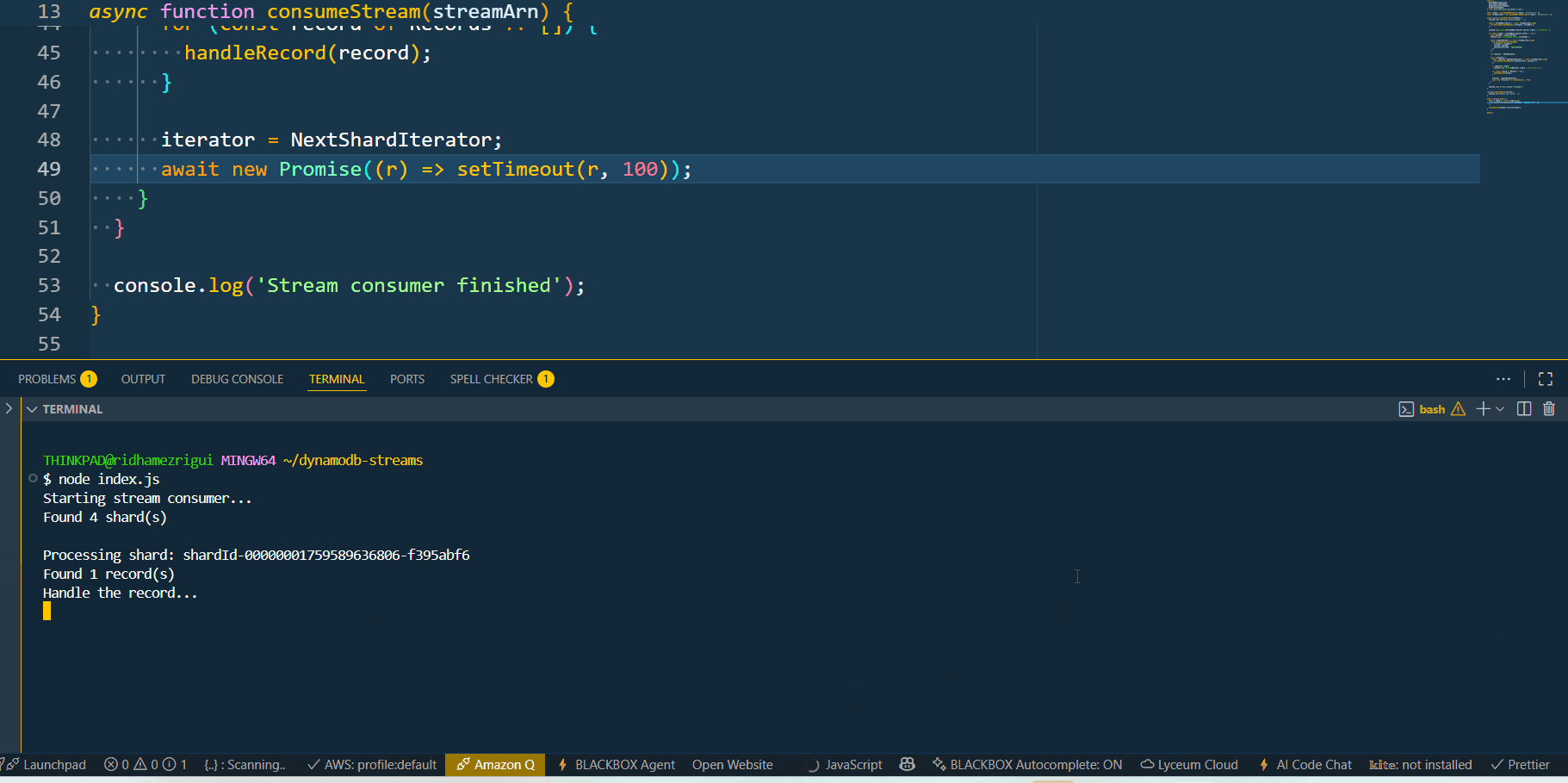
Testing
Conclusion
AWS DynamoDB Streams transforms NoSQL databases into event-driven powerhouses, capturing every insert, update, or delete as a real-time event. By integrating with Lambda functions, Kinesis Data Streams, or custom Node.js consumers, we can build reactive systems that power real-time analytics, cross-region replication, cache invalidation, and AI-driven workflows. Instead of treating DynamoDB as just a static datastore, Streams turns it into a live data pipeline that enables modern, event-driven architectures where services respond to changes without tight coupling or constant polling.